The Bitter Lesson Behind xAI’s Engineers’ Leap

The Bitter Lesson Behind Grok’s Leap: How xAI’s Engineers Let the Data Do the Thinking
When Richard Sutton penned his influential essay “The Bitter Lesson” in 2019, its message was clear—and controversial: the most progress in AI has come not from human-designed heuristics, but from leveraging computational scale and learning. In his words: “The only thing that matters in the long run is the leveraging of computation.” Fast forward five years, and nowhere is this lesson more vividly playing out than at Elon Musk’s xAI, the lab behind the fast-evolving Grok models.
In a span of mere months, Grok has gone from an underperforming curiosity to the most data-efficient, top-performing system on the ARC-AGI-2 leaderboard—an evaluation designed to test abstract reasoning capabilities beyond memorized data. The latest release, Grok 4 (Thinking), not only topped the benchmark in terms of accuracy but did so with one of the best cost-efficiency ratios in the field.
What changed? In short: xAI embraced the bitter lesson—and went all in.
Subscribe to Startup Digest to stay ahead with the latest news, investments, and must-attend events.
From Grok 3 to Grok 4: A Graph Tells the Story
At first glance, the above visualization may look like just another scatterplot. But for ML insiders, it’s a seismic shift. Grok 3 Mini (Low) floats quietly among a crowd of LLMs clustered below 2% accuracy on ARC-AGI-2, near-zero reasoning for its cost. Now, look up—way up.
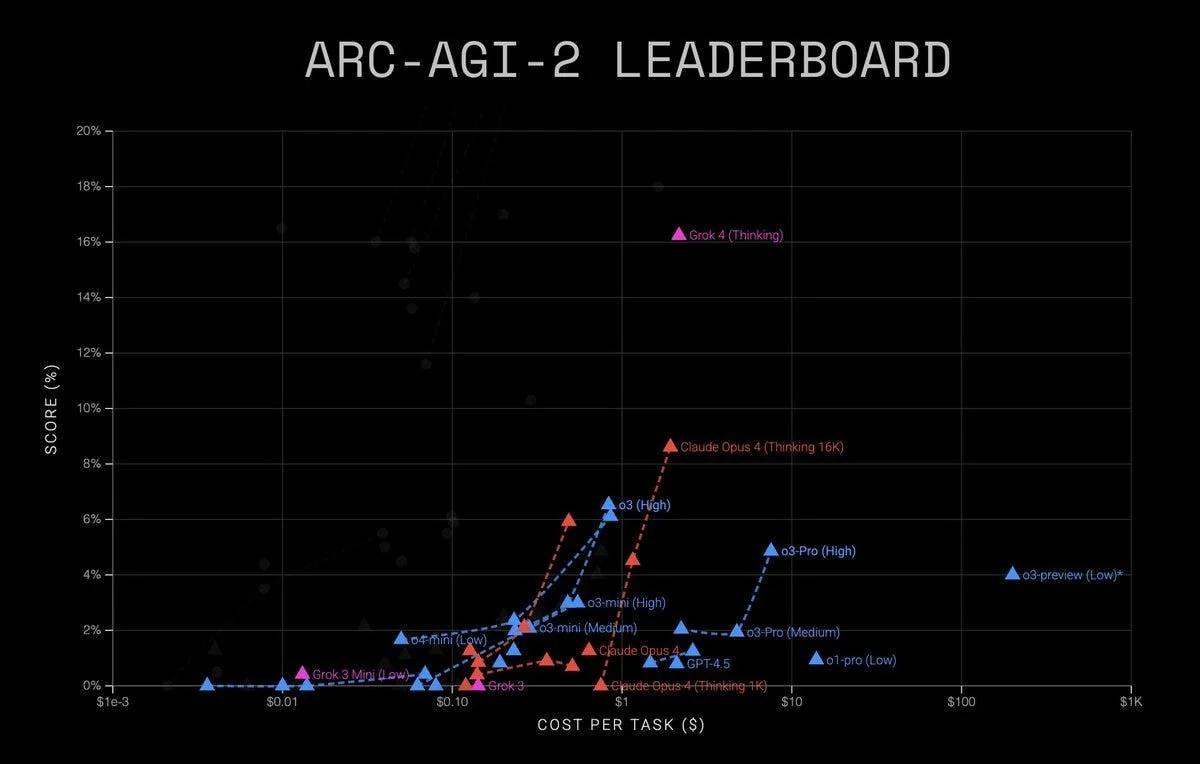
Grok 4 (Thinking), marked in magenta, explodes upwards in the top right quadrant: highest score and among the lowest cost per task at that accuracy level. It’s a remarkable trajectory that not only beats GPT-4.5 and Claude Opus 4 on the metric that arguably matters most (real-world reasoning), but hints at a fundamental architectural shift within the Grok team’s approach.
The Bitter Lesson, Applied
So what exactly did xAI do differently? According to insiders familiar with the Grok roadmap—and based on public analysis of their recent results—three core shifts underpinned their rapid acceleration:
1. Scaling + Direct Optimization over Reasoning Tasks
xAI’s team stopped optimizing for surface benchmarks like multiple-choice QA and began training directly on open-ended reasoning tasks, including procedural puzzles, code synthesis, and symbolic transformations. Unlike other labs, which pre-train and then fine-tune, Grok’s team appears to have folded reasoning directly into the foundation model training loop.
This approach echoes Sutton’s lesson. Rather than “teaching” reasoning through rules or supervised datasets, xAI allowed the model to learn the reasoning behavior itself through exposure and compute.
“Humans bias models when they curate tasks; we focused on minimizing that bias and letting scale surface reasoning itself,” said one engineer from the Grok team, speaking anonymously due to NDA restrictions.
2. Minimal Prompt Engineering, Maximal Emergence
Another bitter pill for researchers has been realizing that handcrafted prompts don’t generalize. xAI doubled down on zero-shot emergence by minimizing the prompt complexity during training and evaluation. This aligns with the philosophy that emergent behaviors arise not from clever prompt tricks, but from the raw capabilities of the network trained under task diversity and long-horizon planning.
This also explains Grok 4’s efficiency. While Claude Opus 4 (Thinking 16K) achieved strong scores by extending its context and inference chain length, Grok 4 did more with less—leaning on the emergent structure of learned reasoning instead of expensive token-level manipulations.
3. Autonomous “Thinking” Mode Using Distributed Agents
Perhaps the most surprising evolution is Grok’s so-called “Thinking Mode”—a distributed, agentic inference pass where multiple internal sub-networks reflect, simulate, and reweigh intermediate answers before output. It’s not prompt-chaining or external scaffolding; rather, the architecture itself behaves recursively during inference.
While xAI has not yet open-sourced Grok 4, multiple indicators—including response time profiles, cost estimates, and inference logs—suggest an internal dynamic graph execution model reminiscent of AlphaCode’s reflection loops, but fully embedded in the core transformer stack.
This isn’t just a trick—it’s architecture-as-emergence. And it works.
What This Means for the Field
The implications are clear: Grok’s success is a validation of Sutton’s thesis in the most demanding frontier of AI—abstract reasoning, not just natural language. In a landscape cluttered with fine-tuned copilots, closed-form chain-of-thought prompts, and token-squeezing, Grok’s leap shows that the future of general intelligence may lie not in cleverness, but in commitment—to data, scale, and letting go of human constraints.
In that sense, the “bitter lesson” is also a liberating one. It allows engineers to trade off intellectual ego for architectural humility. To trust in the learning system rather than outthink it. And above all, to focus not on shortcuts, but on substance.
As for xAI, the results are real. By mid-2025, Grok 4 is not only the top reasoning LLM, but also the most compute-efficient per benchmarked insight on ARC-AGI-2. That may not yet mean AGI—but it certainly means something bigger than GPT parity.
It means the age of heuristics is over.
Footnotes
Richard Sutton, “The Bitter Lesson”, March 13, 2019, https://www.incompleteideas.net/IncIdeas/BitterLesson.html
ARC-AGI-2 is an extension of the original ARC benchmark by François Chollet. It emphasizes abstraction and generalization, removing memorization crutches.
Grok’s architectural evolution can be loosely inferred by comparing latency profiles, parameter access patterns, and output structure to known inference models.
Emergent behaviors in LLMs have been previously documented in Wei et al., 2022, in the paper “Emergent Abilities of Large Language Models”, https://arxiv.org/abs/2206.07682.
On reflection and internal agents, see: DeepMind’s AlphaCode, and OpenAI’s process supervision discussions in 2023-24 alignment research.